سبد اکانت پایگاه های اطلاعاتی
سبد اکانت پایگاه های اطلاعاتی  سبد منابع اطلاعاتی
سبد منابع اطلاعاتی 




امروزه دادهها نقشی حیاتی در پیشبرد تحقیقات علمی ایفا میکنند. اشتراکگذاری و دسترسی آسان به این دادهها، برای تسریع روند پژوهش و افزایش اعتبار نتایج، از اهمیت بالایی برخوردار است. مندلی دیتا (Mendeley Data) به عنوان یک مخزن رایگان و مبتنی بر ابر، این امکان را برای پژوهشگران فراهم میکند تا دادههای خود را به اشتراک گذاشته و از دادههای دیگران بهرهمند شوند.
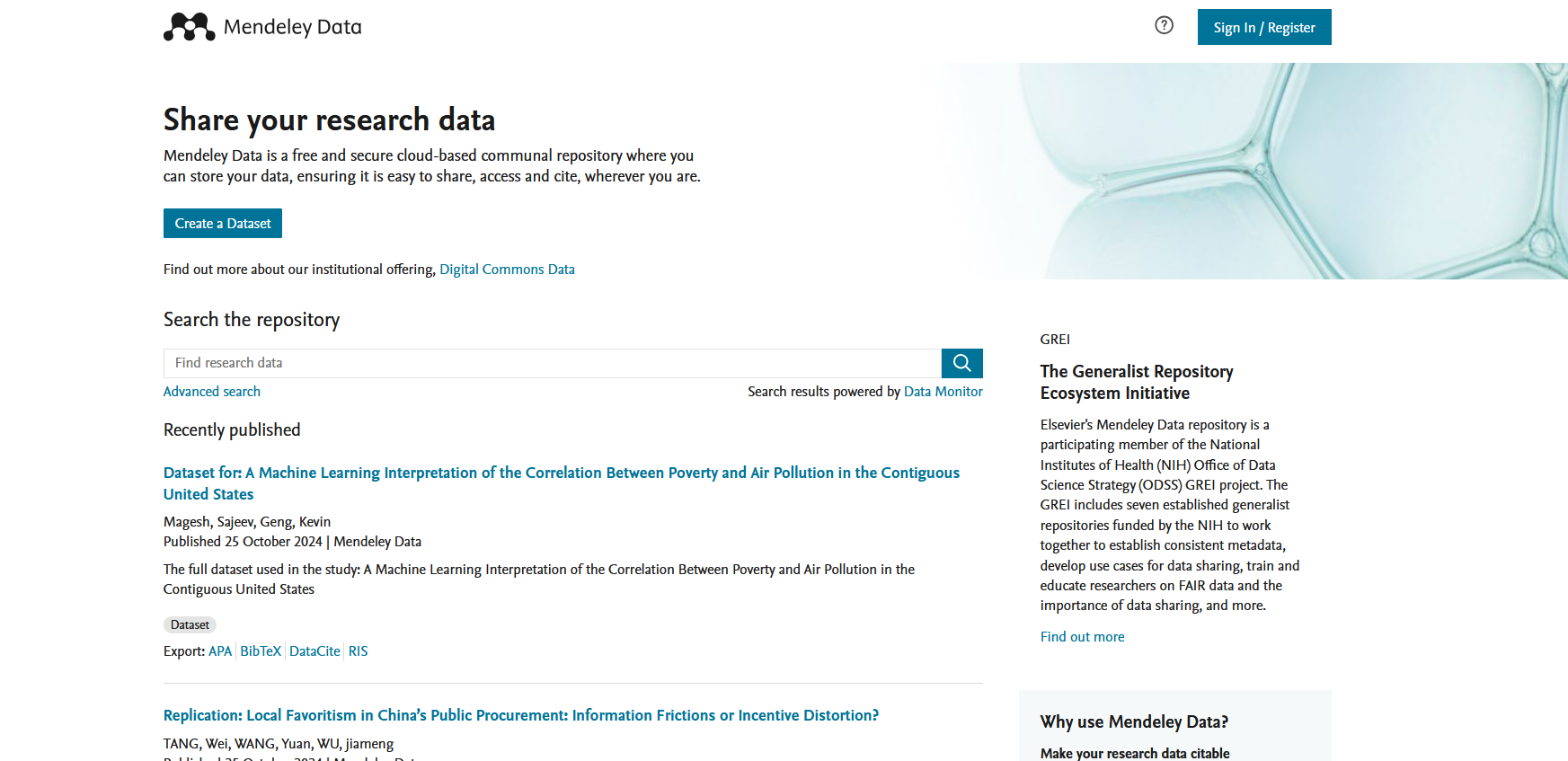
پایگاه داده های پژوهشی مندلی دیتا Mendeley Data چیست؟
مندلی دیتا یک پلتفرم آنلاین رایگان و امن است که به پژوهشگران اجازه میدهد دادههای پژوهشی خود را ذخیره، به اشتراک بگذارند و به آنها ارجاع دهند. این پلتفرم توسط شرکت الزویر (Elsevier) ارائه میشود و با هدف تسهیل همکاریهای علمی و افزایش شفافیت در تحقیقات ایجاد شده است.
تاریخچه مندلی دیتا
مندلی در سال ۲۰۰7 به عنوان یک نرمافزار مدیریت مراجع علمی تأسیس شد و به تدریج با افزودن امکانات جدید، به یک پلتفرم جامع برای پژوهشگران تبدیل گردید. مندلی دیتا به عنوان بخشی از این توسعه، با هدف فراهم کردن بستری برای ذخیره و اشتراکگذاری دادههای پژوهشی ایجاد شد.
محتوای مندلی دیتا
مندلی دیتا با بیش از ۴۳ میلیون مجموعه داده، یک منبع عظیم از اطلاعات پژوهشی است. این دادهها شامل انواع مختلفی از جمله دیتاستها، تصاویر، ویدیوها، فایلهای متنی، دادههای خام حاصل از آزمایشها و غیره میشود. این دادهها در بازه زمانی گستردهای از سال ۱۹۷۰ تا ۲۰۲۵ منتشر شدهاند که نشاندهنده پوشش وسیع موضوعات و زمانهای مختلف است.
دادههای پژوهشی چیست؟
اساس علم را دادههای پژوهشی تولید شده توسط پژوهشگران تشکیل میدهد که با اشتراکگذاری آنها میتوان به پیشبرد بیشتر علم و پژوهش کمک کرد، اشتراکگذاری و به دنبال آن دسترسپذیری دادههای پژوهشی قابلیتهای زیادی برای پیشرفتهای علمی فراهم کرده است و باعث تسهیل در بازتولید نتایج پژوهشها شده است(۱)، ترویج پژوهشهای جدید، تقویت انسجام پژوهشهای پیشین، تسهیل فرصتهای یادگیری دانشجویان، جلوگیری از جمعآوری دوباره دادههای تکراری، افزایش اثر پژوهشها، افزایش شهرت دانشگاهی، پذیرش سیاستهای حامیان مالی پژوهشها و الزامات نشریات، اعتبار یابی پژوهشها، آزمون فرضیههای جدید با استفاده از دادههای موجود و کمک به پیشبرد علم ازجمله مزایای اشتراکگذاری دادهها هست.
مدیریت صحیح دادههای پژوهشی موجب میشود که پژوهشگران هم خود بتوانند بعدها به دادهها مراجعه کنند و در پژوهشهای دیگر خود از آنها استفاده نمایند، و هم با اشتراکگذاری دادهها این امکان را برای سایر پژوهشگران فراهم نمایند که بتوانند آن دادهها را برای اهداف دیگر مورد استفاده قرار دهند در حال حاضر بیشتر پژوهشگران علاوه بر مقاله، دادههای پژوهشی(دادههایی که برای تحلیل و ارائه نتایج یک پژوهش بهصورت رقومی جمعآوری، مشاهده و یا تولید شده است و شامل: دادههایی است که در نرمافزارهای مختلف مانند SPSS , Excel و … ذخیره شدهاند) خود را نیز ارسال میکنند تا برای عموم مردم دسترسپذیر باشد.
اکنون پایگاههایی که خدمات اینگونه ارائه میدهند، رو به رشد میباشند مثالهایی از این دست عبارتاند از پایگاه مندلی که پژوهشگران در بخش دیتاست(مجموعه داده) میتوانند دادههای پژوهشی را بارگذاری کرده و دیگران از آن استفاده کنند یا دانشگاه هاروارد که با Harvard Dataverse خدمات ارائه میدهد.
در الزویر ما بر این باور هستیم که ۱۰ مرحله برای ایجاد دادههای مؤثر وجود دارد که میتواند مانند یک نقشه راه برای توسعه بهتر فرایندهای مدیریت دادهها در طول چرخه حیات داده عمل کند، این موارد شامل:

این 10 لایه، به همراه مرحله یکپارچهسازی بهعنوان یک اصل هدایت شده است که توسط آن میتوان اقدامات مرتبط به مدیریت دادههای پژوهشی را انجام و بررسی کرد.
ویژگیهای مندلی دیتا
- قابل استناد کردن دادهها: با تخصیص DOIهای منحصربهفرد، دادههای پژوهشی به راحتی قابل ارجاع و استناد میشوند.
- اشتراکگذاری دادهها به صورت عمومی یا خصوصی: پژوهشگران میتوانند دادههای خود را به صورت عمومی منتشر کرده یا به صورت خصوصی با همکاران خود به اشتراک بگذارند.
- ذخیرهسازی بلندمدت دادهها: دادهها به صورت بلندمدت در مخزن ذخیره میشوند و از طریق خدمات Data Archiving & Networked Services (DANS) بایگانی میگردند.
- دسترسی به نسخههای مختلف دادهها: پشتیبانی از نسخهبندی دادهها، امکان مدیریت و دسترسی به نسخههای مختلف را فراهم میکند.
- ارتباط مقاله با دادهها: با استفاده از DOI منحصربهفرد، میتوان مقالات را به دادههای مرتبط متصل کرد.
کاربردهای مندلی دیتا
- ذخیرهسازی امن دادههای پژوهشی: پژوهشگران میتوانند دادههای خود را در یک مخزن امن ذخیره کرده و در هر زمان به آن دسترسی داشته باشند.
- اشتراکگذاری دادهها با همکاران: امکان اشتراکگذاری دادهها با همکاران قبل از انتشار، همکاریهای پژوهشی را تسهیل میکند.
- افزایش دیدهشدن دادهها: با انتشار عمومی دادهها و تخصیص DOI، امکان دسترسی سایر پژوهشگران به دادهها فراهم شده و به افزایش ارجاعات کمک میکند.
- حفظ یکپارچگی دادهها: نسخهبندی دادهها به پژوهشگران امکان میدهد تغییرات را پیگیری کرده و یکپارچگی دادهها را حفظ کنند.
روش دسترسی به مندلی دیتا:
دسترسی به این پایگاه رایگان است و نیازمند پرداخت هزینه ای نیست. لذا میتوانید به صفحه این پایگاه به آدرس: https://data.mendeley.com/research-data رفته و داده خود را جستجو کنید.
سوالات متداول درباره مندلی دیتا
منبع:
https://www.mendeley.com/datasets